
Ollama 是一个免费的开源应用程序,它允许你在自己的电脑上运行各种大型语言模型,包括 Llama 3.1, Mistral, Gemma 2等,即使在资源有限的情况下也可以做到。Ollama 利用 llama.cpp 的性能提升,这个开源库旨在使你能够在本地以相对较低的硬件要求运行大型语言模型(LLM)。此外,它还包含一种包管理器,只需一个命令即可快速有效地下载和使用大型语言模型。
Ollama快速上手
- 下载 Ollama
- 运行
Ollama llama3
ollama run llama3
运行后, 就可以在终端和大模型对话了
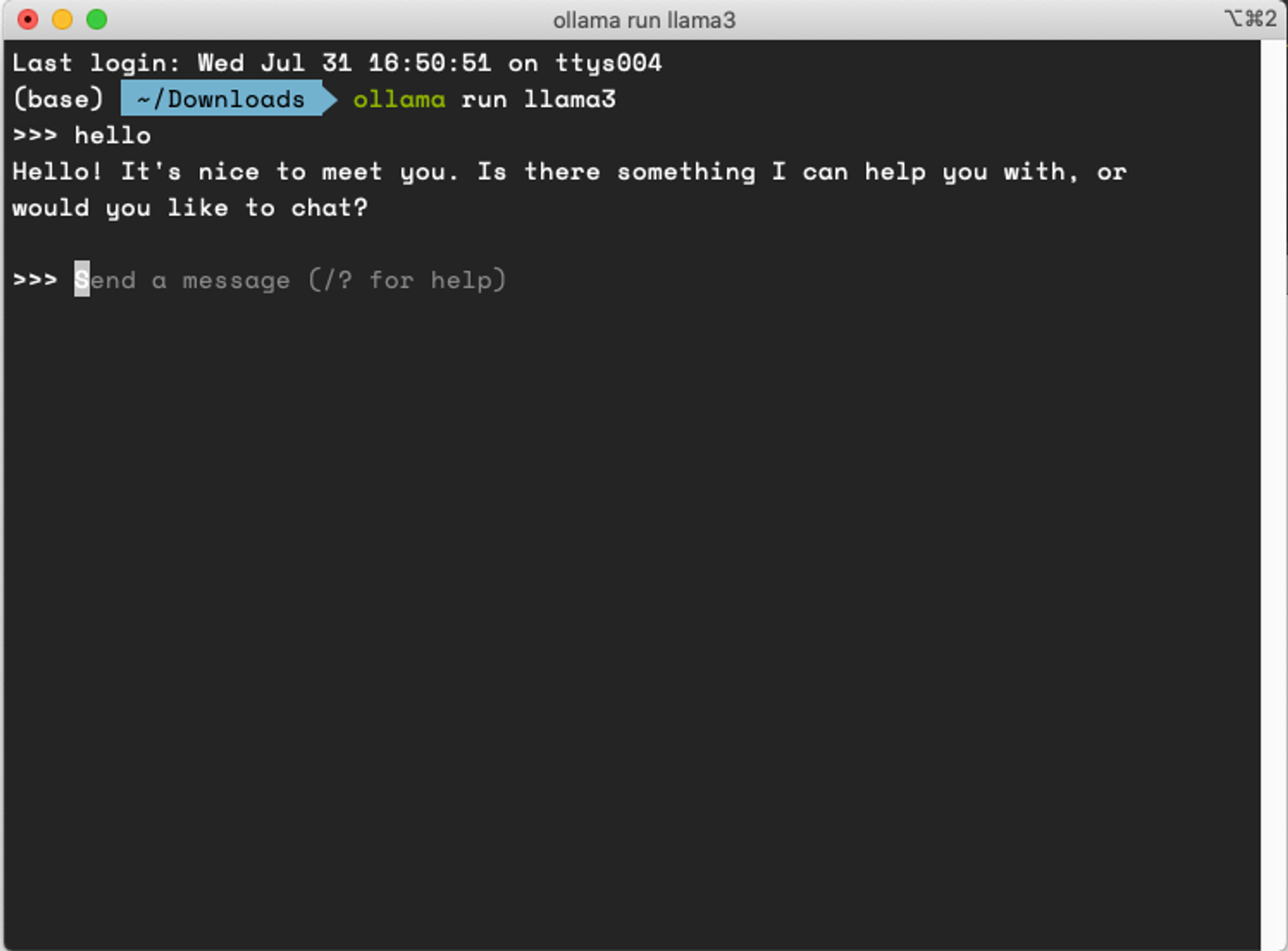
启动成功后,Ollama 在本地 11434 端口启动了一个 API 服务,可通过 http://localhost:11434 访问。
- Ollama API
Ollama 提供了一个 REST API,用于运行和管理模型。
生成响应
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'
与模型对话
curl http://localhost:11434/api/chat -d '{
"model": "llama3.1",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'
命令行与接口访问使用起来不太方便,我们下一步用 dify 给 Ollama 套上一个漂亮的外壳。
构建本地Dify服务
-
克隆源代码
git clone https://github.com/langgenius/dify.git -
启动
difycd dify/docker cp .env.example .env docker compose up -d -
访问 http://localhost 配置账号即可
更多详细说明可参考 官方文档
用Dify给Ollama套上外壳
(1) 添加模型供应商 Ollama
在 设置 > 模型供应商 > Ollama 中配置如下:
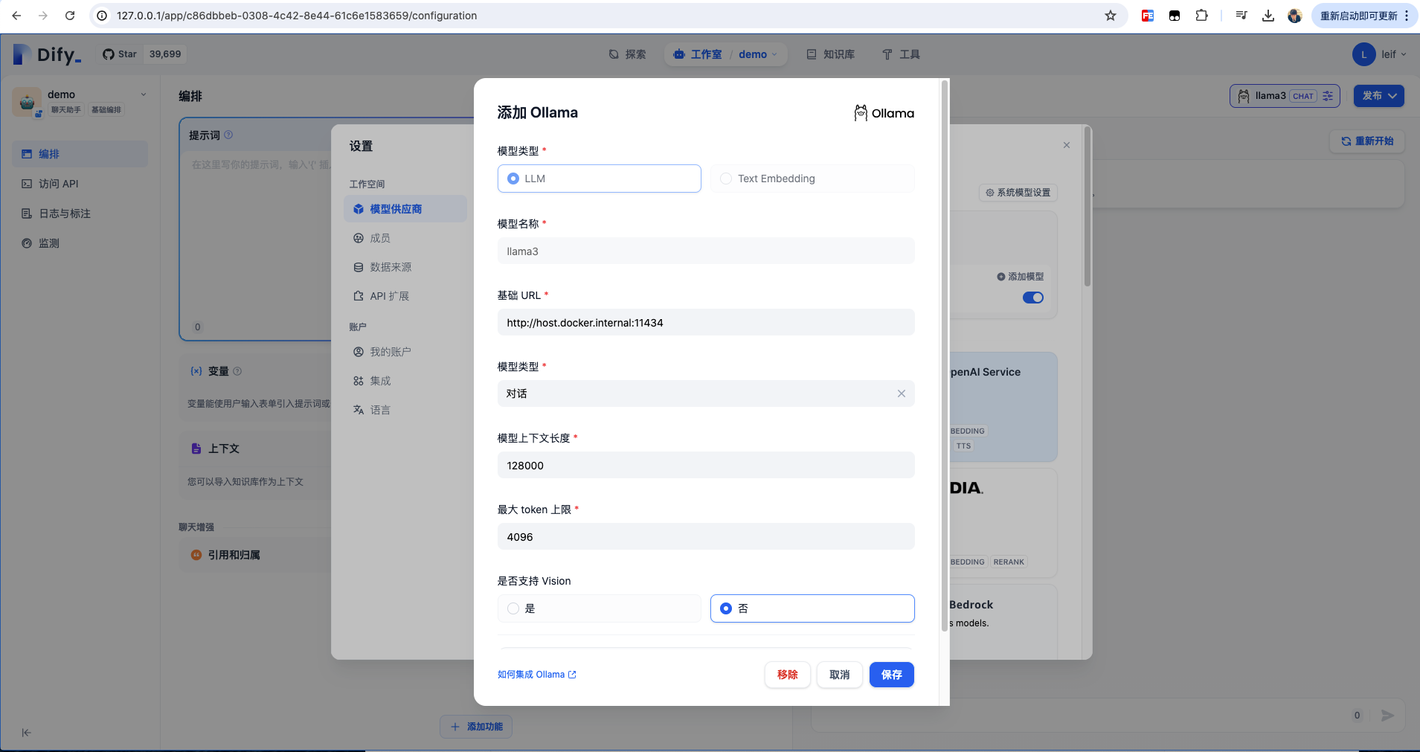
注:因为 dify 是docker 部署,基础url 填写 http://localhost:11434 访问到的是docker容器的本地地址,会出现错误。填入 http://host.docker.internal:11434 即可。(此部分官方文档有说明)
(2) 在应用中使用 Ollama 模型
总结
Meta 的 Llama 3 发布以及其大语言模型(LLM)技术的开源是科技界的一大里程碑。现在,这些先进模型可以通过 Ollama 和 Dify 等本地工具进行访问,普通人也能利用其巨大潜力来生成文本、翻译语言、进行创意写作等。此外,API 的提供使开发人员能够轻松地将大语言模型集成到新项目中或增强现有项目。通过 Llama 3 等开源计划,大语言模型技术的民主化最终开启了广阔的创新可能性。